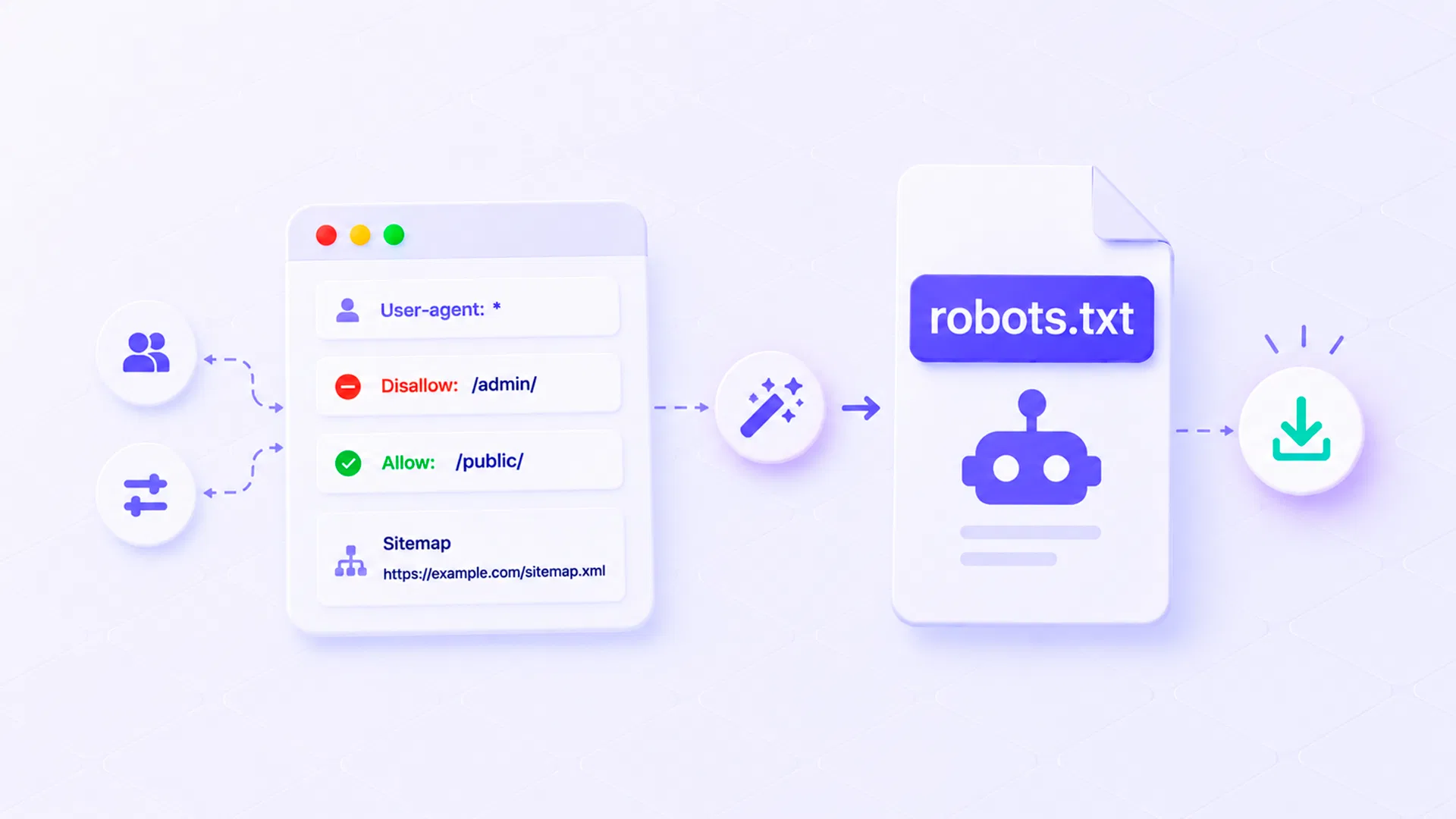
Что такое robots.txt
Robots.txt — это текстовый файл, который подсказывает поисковым роботам, какие разделы сайта можно обходить, а какие лучше не трогать.
Обычно он лежит в корне сайта:
https://example.com/robots.txtВнутри файла находятся правила для роботов. Например:
User-agent: *
Disallow: /admin/
Disallow: /cart/
Sitemap: https://example.com/sitemap.xmlЕсли объяснять без технического жаргона, robots.txt — это инструкция для поисковых систем:
- сюда можно заходить;
- сюда лучше не заходить;
- вот где лежит карта сайта;
- для разных роботов могут действовать разные правила.
Но важно сразу снять главное заблуждение.
Robots.txt управляет обходом сайта, а не гарантированной индексацией или удалением страниц из поиска.
Если закрыть страницу через Disallow, поисковик может не скачать её содержимое. Но сам URL иногда всё равно может появиться в поиске, если на него есть ссылки с других страниц. Поэтому robots.txt нельзя воспринимать как инструмент приватности или как универсальный способ «убрать страницу из Google».
Robots.txt — это не замок на двери. Это табличка для робота: «сюда не ходи». Добросовестные поисковики её учитывают, но файл не защищает приватные данные и не гарантирует удаление URL из поиска.
Зачем robots.txt бизнесу
Для бизнеса robots.txt важен не как технический файл сам по себе. Важен результат: поисковые системы должны обходить нужные страницы и не тратить ресурсы на технический мусор.
Если правила настроены неправильно, сайт может терять органический трафик по очень приземлённым причинам:
- поисковик не видит важные посадочные страницы;
- CSS или JavaScript закрыты от обхода, и страница плохо рендерится;
- робот тратит обход на фильтры, параметры, корзину, поиск по сайту и технические URL;
- после редизайна старые правила случайно закрывают новые разделы;
- sitemap.xml показывает страницы, а robots.txt запрещает их обходить;
- команда думает, что страница «скрыта», хотя URL всё ещё может появляться в поиске.
На практике я часто вижу проекты, где robots.txt когда-то настроили «на всякий случай», а потом годами не возвращались к файлу. За это время меняется CMS, появляются новые разделы, запускается блог, меняется структура URL — а старые правила продолжают влиять на обход сайта.
Именно поэтому robots.txt полезно рассматривать не отдельно, а как часть технического SEO: вместе с sitemap.xml, canonical, noindex, редиректами, статусами ответа сервера и JavaScript-рендерингом.
Польза для бизнеса - Что даёт правильно настроенный robots.txt
- Контроль обхода. Можно ограничить обход технических разделов, служебных URL, корзины, внутреннего поиска и параметров.
- Меньше технического мусора. Поисковый робот меньше отвлекается на страницы, которые не должны участвовать в поиске.
- Безопаснее релизы. После редизайна, миграции или смены CMS проще проверить, не закрыты ли важные страницы.
- Связка с sitemap.xml. В robots.txt можно указать путь к sitemap.xml, чтобы поисковики быстрее находили карту сайта.
- Понятнее техническая архитектура. Файл показывает, какие зоны сайта команда считает открытыми или закрытыми для обхода.
- Быстрее находятся ошибки. Конфликты robots.txt с sitemap, noindex и canonical часто сразу показывают проблемы технического SEO.
Чем robots.txt отличается от noindex
Одна из самых дорогих ошибок — путать robots.txt и noindex.
Они решают разные задачи.
Robots.txt отвечает на вопрос:
Можно ли роботу заходить по этому URL и скачивать содержимое?
Noindex отвечает на другой вопрос:
Можно ли показывать эту страницу в поисковой выдаче?
Из-за этого возникает важный нюанс: если вы закрыли страницу в robots.txt, поисковик может не увидеть noindex внутри HTML. То есть вы как будто говорите: «не заходи на страницу», а потом внутри страницы оставляете инструкцию, которую робот уже не может прочитать.
Практический вывод простой:
- если нужно ограничить обход технической зоны — используйте robots.txt;
- если нужно убрать страницу из индекса — используйте
noindex, удаление страницы, пароль или другие методы; - если страница уже есть в индексе, не закрывайте её в robots.txt до того, как поисковик увидит
noindex.
Как устроен robots.txt
Базовый robots.txt состоит из групп правил.
Пример:
User-agent: *
Disallow: /admin/
Disallow: /cart/
Allow: /assets/
Sitemap: https://example.com/sitemap.xmlГлавные директивы:
User-agent— к какому роботу относятся правила;Disallow— что нельзя обходить;Allow— что можно обходить, даже если родительская директория закрыта;Sitemap— где лежит sitemap.xml.
User-agent
User-agent указывает, для какого робота действует блок правил.
User-agent: *
Disallow: /admin/Звёздочка означает «для всех роботов».
Можно задавать отдельные правила для конкретных роботов:
User-agent: Googlebot
Disallow: /test/
User-agent: *
Disallow: /admin/Для бизнеса здесь важно не пытаться писать слишком сложные правила без необходимости. Чем сложнее robots.txt, тем выше риск случайно закрыть важные страницы.
Disallow
Disallow запрещает обход указанного пути.
Disallow: /admin/Это не значит, что раздел защищён. Это значит, что добросовестный робот должен не обходить URL, начинающиеся с /admin/.
Самая опасная строка:
Disallow: /Она закрывает от обхода весь сайт для указанного User-agent.
Иногда такую строку используют на тестовом окружении, а потом случайно переносят в продакшен. После этого бизнес видит падение органического трафика, а причина оказывается в одном символе.
Allow
Allow помогает сделать исключение внутри закрытого раздела.
Например:
User-agent: *
Disallow: /catalog/
Allow: /catalog/public/Такой подход нужен редко, но бывает полезен на сложных сайтах. Главное — не превращать robots.txt в лабиринт исключений, который никто в команде не понимает.
Sitemap
В robots.txt стоит указывать путь к sitemap.xml:
Sitemap: https://example.com/sitemap.xmlЕсли карт сайта несколько, можно указать несколько строк:
Sitemap: https://example.com/sitemap-pages.xml
Sitemap: https://example.com/sitemap-posts.xml
Sitemap: https://example.com/sitemap-products.xmlRobots.txt и sitemap.xml работают в связке: один файл ограничивает обход, другой показывает важные URL. Если они противоречат друг другу, поисковики получают смешанные сигналы.
Что можно и нельзя закрывать в robots.txt
Хороший robots.txt не должен закрывать всё подряд. Его задача — аккуратно ограничивать обход там, где это действительно нужно.
Обычно можно закрывать:
- админские разделы;
- служебные URL;
- корзину;
- оформление заказа;
- внутренний поиск;
- временные тестовые разделы;
- технические параметры;
- некоторые фильтры и сортировки;
- страницы, которые не должны тратить crawl budget.
Но нельзя бездумно закрывать:
- главную страницу;
- страницы услуг;
- статьи блога;
- категории;
- карточки товаров;
- CSS и JavaScript, которые нужны для рендера;
- изображения и файлы, важные для отображения страницы;
- URL из sitemap.xml;
- страницы, на которых поисковик должен увидеть canonical или noindex.
Особенно аккуратно нужно относиться к современным frontend-сайтам. Если поисковик не может получить CSS, JS или данные, нужные для нормального рендера, он может хуже понять страницу.
На проектах с React, Next.js, SPA, headless CMS и сложным lazy loading проблема часто оказывается не только в robots.txt, но и в реализации frontend-части. В таких случаях техническое SEO пересекается с разработкой: нужно смотреть, как страница отдаётся поисковику, какие ресурсы доступны и что видно без пользовательских действий.
Не уверены, что robots.txt не закрывает важные страницы?
Проверим robots.txt, sitemap.xml, noindex, canonical, редиректы, доступность ресурсов и то, как поисковики реально видят ваш сайт.
Частые ошибки в robots.txt
Ошибки в robots.txt часто выглядят незаметно. Файл открывается, синтаксис кажется нормальным, сайт работает для пользователей — но поисковый робот получает неправильные инструкции.
Закрыли весь сайт
Самая опасная ошибка:
User-agent: *
Disallow: /Для тестового окружения это может быть нормально. Для продакшена — катастрофа.
После релиза такая строка может привести к тому, что поисковики перестанут обходить сайт. Иногда проблему замечают только после падения органического трафика.
Закрыли важные посадочные страницы
Например:
Disallow: /services/Если в этом разделе находятся коммерческие страницы услуг, сайт сам запрещает роботам их обходить.
Для бизнеса это особенно болезненно: страницы есть, тексты написаны, дизайн сделан, но поисковик не может нормально их обработать.
Закрыли CSS и JavaScript
Иногда в robots.txt закрывают технические папки слишком широким правилом:
Disallow: /assets/
Disallow: /static/Если там лежат CSS, JavaScript или изображения, нужные для рендера, поисковик может хуже понять страницу.
Для современных сайтов это критично: поисковик должен видеть не только HTML, но и ресурсы, от которых зависит отображение контента.
Перепутали robots.txt и noindex
Например, команда хочет убрать страницу из поиска и делает так:
Disallow: /old-page/Но если URL уже известен поисковику и на него есть ссылки, он может продолжать появляться в результатах без нормального сниппета.
Правильнее сначала дать поисковику увидеть noindex или использовать другие методы удаления из индекса, а не просто закрывать обход.
Robots.txt конфликтует с sitemap.xml
Одна из частых проблем:
Disallow: /blog/
Sitemap: https://example.com/sitemap.xmlА в sitemap.xml при этом лежат статьи:
https://example.com/blog/article-1/
https://example.com/blog/article-2/Получается противоречие: sitemap говорит «вот важные страницы», а robots.txt говорит «не обходи этот раздел».
Закрыли приватные разделы только через robots.txt
Например:
Disallow: /private/
Disallow: /clients/
Disallow: /backup/Это плохая идея, если там действительно приватные данные. Robots.txt публичен, и такой файл может даже подсказать любопытному человеку, где искать закрытые разделы.
Для приватных данных нужны авторизация, ограничения доступа, правильные статусы ответа и безопасность на уровне сервера.
Слишком сложные правила
Иногда robots.txt превращается в длинный список исключений, который никто не понимает:
Disallow: /*?sort=
Disallow: /*?filter=
Allow: /*?filter=brand
Disallow: /catalog/*/reviews/
Allow: /catalog/*/reviews/best/Такие правила могут быть оправданы на больших проектах, но их нужно документировать и регулярно проверять. Иначе через несколько релизов команда уже не понимает, что реально открыто, а что закрыто.
Главный вопрос не в том, «есть ли robots.txt». Главный вопрос — не мешает ли он поисковикам видеть страницы, которые приносят бизнесу заявки, продажи и органический трафик.
Как проверить robots.txt
Проверку robots.txt лучше делать в два этапа.
Сначала проверьте сам файл:
- открывается ли
/robots.txt; - отдаёт ли сервер статус
200 OK; - нет ли синтаксических ошибок;
- нет ли случайного
Disallow: /; - корректно ли указаны
User-agent; - есть ли ссылка на sitemap.xml;
- нет ли устаревших правил после редизайна или миграции.
Для быстрой проверки можно использовать валидатор:
После этого проверьте смысл правил на реальных URL:
- главная страница;
- страницы услуг;
- статьи;
- категории;
- карточки товаров;
- sitemap.xml;
- CSS и JavaScript;
- изображения;
- технические разделы;
- страницы, которые должны быть закрыты.
Если нужно быстро собрать базовый файл, можно использовать генератор:
Но генератор не заменяет SEO-логику. Он помогает создать корректный файл, а дальше важно понять, какие именно разделы сайта нужно открыть или закрыть.
Хотите понять, как поисковики реально видят ваш сайт?
Проверим robots.txt не отдельно, а вместе с sitemap.xml, canonical, noindex, редиректами, статусами ответа, внутренней перелинковкой и frontend-рендерингом.
Когда нужен технический SEO-аудит
Если у вас небольшой сайт и нужно просто создать базовый robots.txt, можно начать самостоятельно: собрать файл в генераторе, проверить валидатором и убедиться, что важные страницы открыты для обхода.
Но если на сайте уже есть органический трафик, блог, каталог, фильтры, редизайн, миграция или проблемы с индексацией, robots.txt лучше проверять в контексте всего технического SEO.
Повод подключать специалиста:
- важные страницы не появляются в поиске;
- после релиза или редизайна упал органический трафик;
- в индексе появились дубли и мусорные URL;
- Search Console показывает проблемы обхода или индексации;
- sitemap.xml и robots.txt противоречат друг другу;
- страницы закрыты через robots.txt, но всё равно видны в поиске;
- сайт на современном frontend-стеке, и нужно проверить рендеринг для поисковиков;
- команда не уверена, какие правила в robots.txt безопасно менять.
В техническом SEO robots.txt — это не изолированный файл, а часть системы. Его нужно смотреть вместе с:
- sitemap.xml;
- canonical;
- noindex;
- редиректами;
- статусами ответа сервера;
- внутренней перелинковкой;
- URL-структурой;
- JavaScript-рендерингом;
- доступностью CSS, JS и изображений;
- поведением сайта после релизов.
Если проблема упирается в реализацию, её нужно не только найти, но и исправить в коде. Поэтому для многих проектов техническое SEO естественно переходит во frontend-разработку: нужно открыть нужные ресурсы, исправить рендеринг, убрать технические дубли и сделать так, чтобы поисковик видел страницу так же понятно, как пользователь.
Хороший robots.txt — это не файл «для галочки». Это способ аккуратно управлять обходом сайта и не мешать поисковикам находить то, что приносит бизнесу заявки, продажи и доверие.
Если вы не уверены, правильно ли настроены robots.txt, sitemap.xml и индексация, лучше начать с аудита. Он покажет, где проблема: в правилах обхода, архитектуре сайта, CMS, frontend-реализации или общей SEO-логике.